スカラーフィールドのスライス操作ガイド (4次元を維持する理由)
Note
このページを読むべき方:
ScalarField を使用していて以下の疑問を感じた場合に参照してください。
field[0]としたのに 1次元配列にならず、4次元のままなのはなぜか?インデクシング操作時に
Shape Mismatchエラーが発生するのはなぜか?squeeze()を使って良いタイミングと、使ってはいけないタイミングはいつか?
ScalarField がインデクシング操作時に4次元構造を常に維持する挙動について説明します。これは NumPy や GWpy の標準的な挙動とは異なり、多次元物理データの整合性を保つための「不変条件」として設計されています。
このページでわかること
以下の要約表は、共有 CSS の表スタイルに合わせてコンパクトに保っています。画面幅が狭い場合は、横スクロールしながら読むのが最も確実です。
項目 |
内容 |
|---|---|
ページ種別 |
ガイド |
対象読者 |
|
前提 |
|
こんなときに読む |
|
検索キーワード |
|
このページの近道
なぜ「4次元」を維持し続けるのか?
実践的な操作例
よくある質問
なぜ「4次元」を維持し続けるのか?
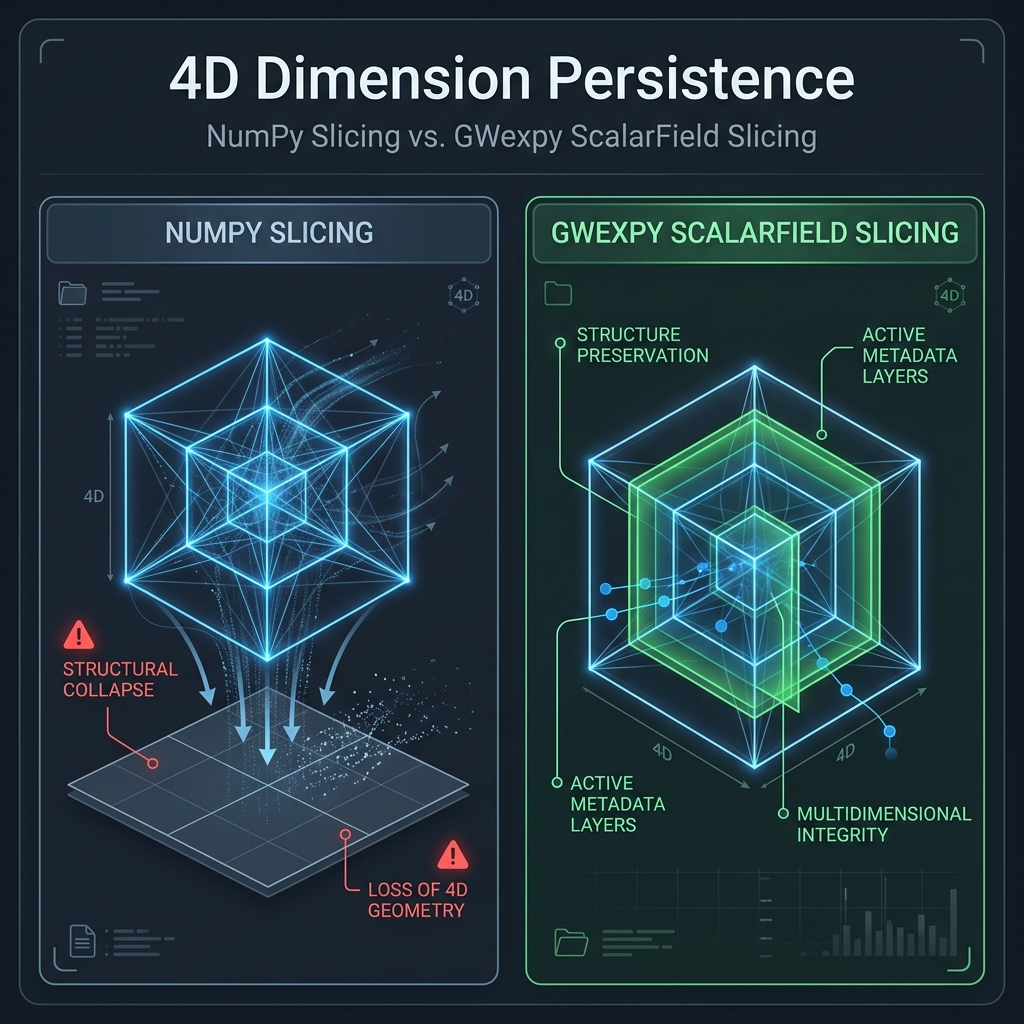
ScalarField は (時間, 周波数, x, y) の 4 つの軸を持つ物理的な「場」を表現します。NumPy のようにスライス時に次元を削減(Rank Loss)しない理由は、主に以下の 4つの柱 によります。
ドメイン情報の保護: 次元を削ると、その軸に紐付いた
t0,f0,dxなどのメタデータが消失し、元の物理空間へ戻れなくなります。FFT/変換の整合性: 常に 4D であることで、どの断面に対しても即座に
fft(),ifft(),spatial_filter()などの多次元演算が可能です。ストリーム処理の安全性: 関数間で受け渡しをする際、次元数が変動しないためプログラムの堅牢性が向上します。
ブロードキャストの一貫性: 常に 4D であるため、計算時の次元合わせ(reshape)の意図がコード上で明確になります。
NumPy vs GWexpy の挙動比較
操作例 |
結果の次元 (NumPy) |
結果の次元 (Field) |
物理的意味 |
|---|---|---|---|
|
3次元 (Rank Loss) |
4次元 (1, F, X, Y) |
特定の時刻の断面(メタデータ維持) |
|
2次元 (Rank Loss) |
4次元 (T, F, 1, 1) |
特定の空間点の時系列(メタデータ維持) |
|
4次元 (維持) |
4次元 (10, F, X, Y) |
時間区間の切り出し |
Caution
.squeeze() 使用時の重大な警告
squeeze() を呼び出して次元を削減すると、削減された軸に紐付くメタデータ(座標情報)は完全に失われます。
一度は削ったデータから field.fft() などを実行しても、正しい物理軸を再構成できなくなるため、squeeze() はプロットや CSV 保存などの「最終出力段階」でのみ使用することを強く推奨します。
実践的な操作例
1. スライシングの挙動
目的: インデクシング後も軸メタデータが残ることを確認する
入力: shape
(100, 50, 10, 10)のScalarField出力: 長さ 1 の軸を保った
snapshotとplane
from gwexpy.fields import ScalarField
import numpy as np
# (time, freq, x, y) = (100, 50, 10, 10)
field = ScalarField(np.zeros((100, 50, 10, 10)), ...)
# 特定の時刻の断面を取得
snapshot = field[50]
# shape は (1, 50, 10, 10) となり、時間軸の情報が残ります。
# 空間断面 (x-y 平面) を抽出
plane = field[:, :, :, 2]
# shape は (100, 50, 10, 1) となり、y軸情報が維持されます。
2. 次元を削減したい場合 (squeeze)
意図的に 1次元や 2次元として扱いたい場合(例:プロットや外部ライブラリへの入力)は、明示的に .squeeze() を呼び出します。
目的: 最終出力段階でだけ次元を落とす
入力: 空間点を切り出した
ScalarField出力: 外部ライブラリに渡しやすい 1 次元配列
# 特定の空間点の時系列を取得してプロット
point_ts = field[:, 2, 5, 5] # (100, 1, 1, 1)
actual_ts = point_ts.squeeze(axis=(1, 2, 3)) # (100,) - これで TimeSeries 互換になります
axis= を明示すると、「どの 1 要素軸を落とすのか」がコード上で分かりやすくなり、意図しない次元削減を避けやすくなります。
3. ブロードキャスト演算の注意点
ScalarField は常に 4次元であるため、NumPy 配列を加減算する場合は形状を合わせる必要があります。
目的: ブロードキャスト時の shape mismatch を避ける
入力:
ScalarFieldと 1 次元補正係数出力: 意図が明示された
reshape(...)付き演算
# ❌ 悪い例: 1次元配列をそのまま足そうとする
field + np.array([1, 2, 3]) # Shape mismatch
# ✅ 良い例: 正しい次元に拡張する
calibration = np.array([1, 2, 3]).reshape(3, 1, 1, 1) # 周波数軸にだけ 3 要素を持たせる
field + calibration
ここで reshape(3, 1, 1, 1) としているのは、「3 要素の補正係数が周波数軸に対応し、時間・x・y 方向には同じ値を使う」ことを明示するためです。
よくある質問 (FAQ)
Q: 常に 4次元だと、1次元の計算時に不便ではありませんか?
A: ScalarField は空間・時間の広がりを持つデータを「場」として扱うためのクラスです。単一チャンネルの単純な時系列を扱う場合は、最初から TimeSeries クラスを使用することをお勧めします。
Q: ScalarField[0, 0, 0, 0] とスカラー抽出した場合は?
A: インデックスがすべてスカラーの場合は、通常の Python スカラー値または NumPy スカラーが返されます。
次に読む
数値安定性 - 4次元演算時の精度管理
アーキテクチャとデータフロー - フィールド API が設計上どこに位置づくかを把握する